
Disks – Not so S.M.A.R.T. After All?
More problems with severe disk performance degradation, but SMART still shows the disc as ‘OK’..
This has now occurred three times over the last 2 years or so, with 1TB and 2TB disks that were around 4+ years old (in continuous use..)..
The contents were still accessible, but data transfer was extremely slow – around 250KiB/s to 1MiB/s.. (and start/stop..)
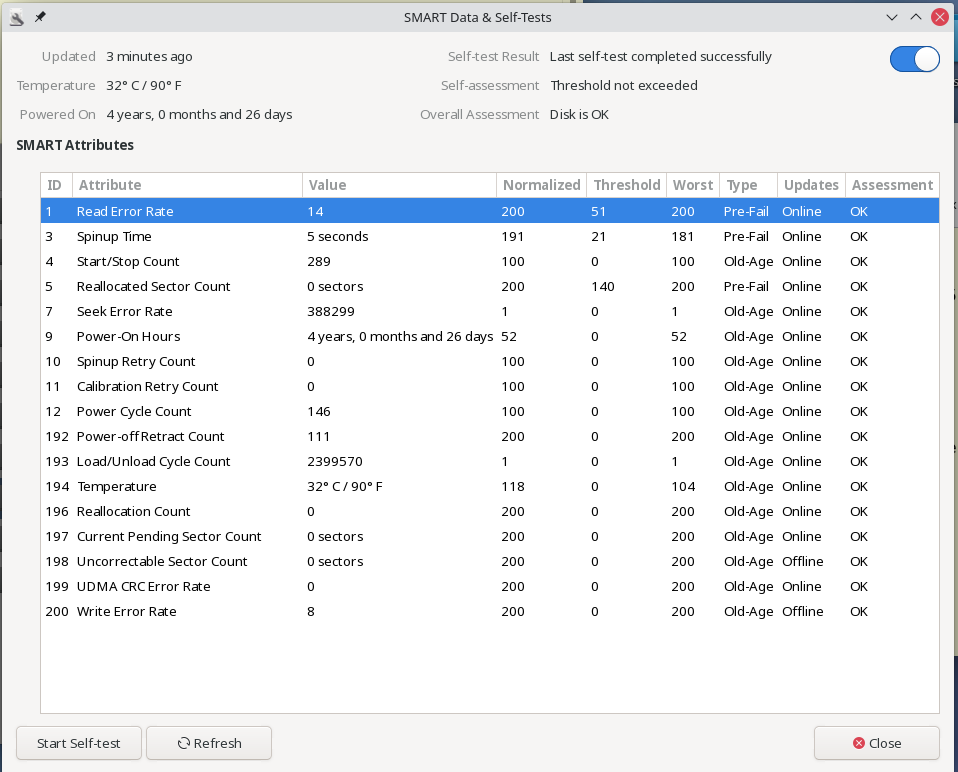
Bad Disk – SMART Data
I was – eventually – able to recover the contents, but the whole process took many days. I tried dd‘ing the disk, but this seemed to go on for ever, so I reverted to copying small batches of files, and checking the destination contents as I went. It would appear that the things to watch out for are ‘Write Error Rate’ and ‘Read Error Rate’, although SMART does not show these as too high? The Threshold for ‘Write Error Rate’ is zero, so I would have thought that a value of 8 would be flagged?
Obviously this is not very scientific, there is no ‘before/after’ and the scenario is very much ‘after the event’.. Eventually I started to see i/o errors, so the snails-pace data recovery was just in time.. Other disks (2TB) of the same brand and vintage are still OK, but these are being swapped out – just in case..
Robert Gadsdon. November 30, 2021.
Hi, the way you describe your problem sounds like you don’t know ddrescue: https://www.gnu.org/software/ddrescue/
Different Linux distros sometimes use variations of the name, like dd-rescue, dd_rescue etc. Essentially they all do the same thing: read the readable parts of the medium first, keep a map of what has been recovered already, then use this map to try to recover the rest during the next pass(es).